Stereo DNN#
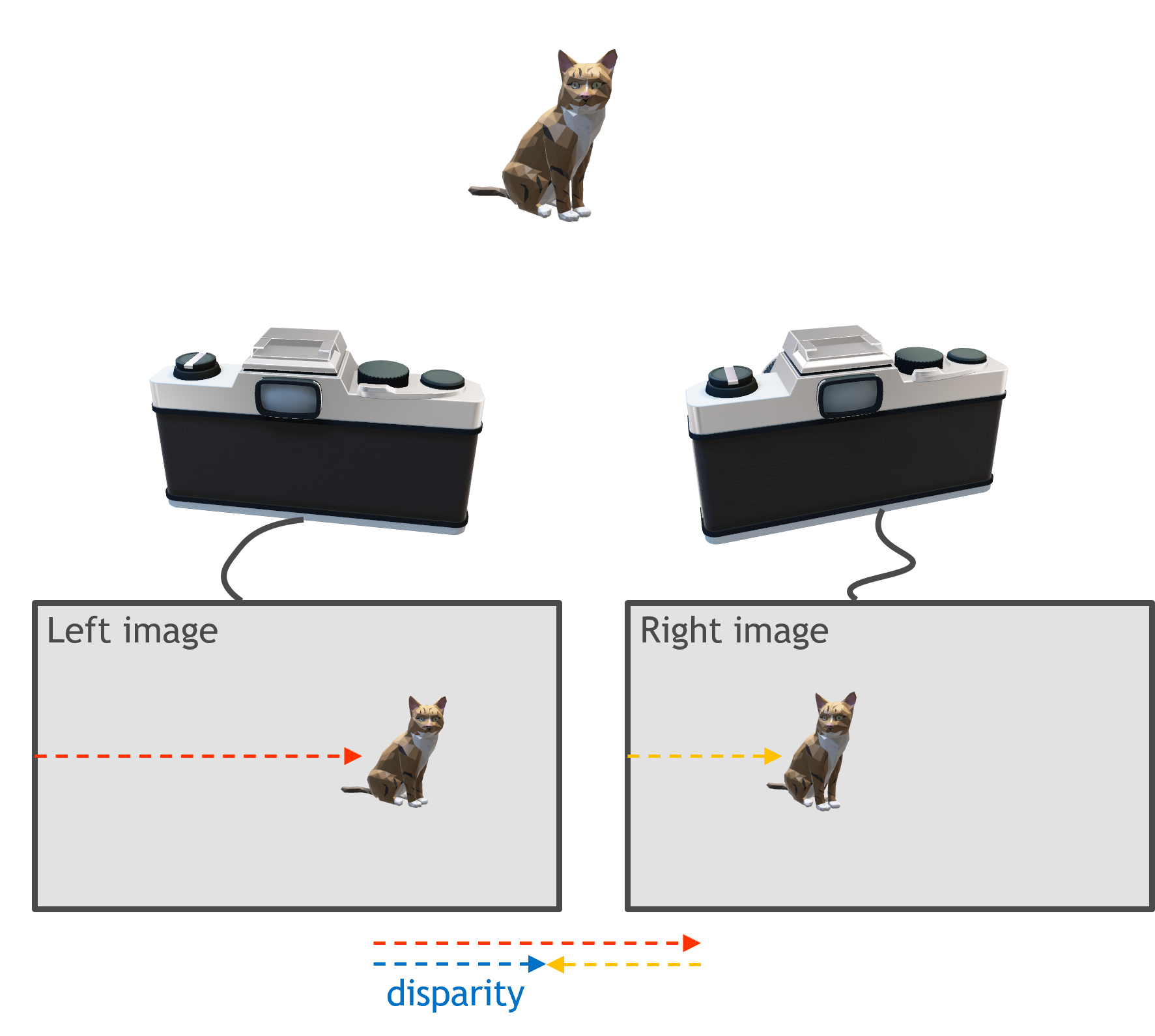
Stereo vision relies on two cameras capturing the same scene with a known geometric offset in their viewing direction. If a given feature appears in both images, the difference between their location in the left/right images is called disparity, and this difference is directly related to the depth of the object.
Pixel Correspondence#
Classical stereo approaches explicitly calculate disparity by matching pixels from the left image to corresponding pixels in the right image. This approach works well if pixel correspondence can be determined. However, many cases exist where pixel correspondence is difficult or impossible to establish. These so called “ill-posed” regions include the following:
Regions with reflections or specular highlights
Regions that are texture-less
Regions that are periodic
Regions that are non-overlapping or self-occluding
Regions that are semi or fully transparent
The cases mentioned can be either difficult or impossible to resolve for certain traditional stereo formulations. Therefore, in some cases, the best possible outcome from a traditional stereo algorithm is to provide no information about these regions.
Stereo DNN Solutions#
Stereo deep neural network (DNN) methods, such as ESS and FoundationStereo, solve the problem differently: Pixel correspondence is not formulated as an explicit task, but rather implicitly guided by the specific model architecture and reinforced with data. As a result, semantic image features and learned priors can be used to establish depth even in ill-posed regions.
In addition, because AI-based methods are data driven, varying amounts of “imperfections” to the assumed stereo geometry can be implicitly accounted for through the training process. These imperfections can include calibration and rectification errors, exposure and camera ISP (image signal processing) differences, and various sources of hardware noise.
The advantages provided by AI-based stereo is evident in popular stereo benchmarks such as Middlebury and KITTI, where AI-based approaches dominate.
Examples#
The example below shows the disparity output between a classical stereo algorithm (SGM, center) and ESS (right). The left panel shows the RGB image from the left camera. There are many difficult regions in this scene, including reflections, featureless surfaces, and occlusions.
Focusing only on the floor, the following figure shows the bottom corner of the image from the left and right camera, respectively, to illustrate the difficulty involved with traditional pixel correspondence. A piece of blue tape, indicated by the arrows, represents a real physical feature.

The difference between the left and right arrows represents the disparity that should be predicted for all pixels along that row in the image. However, it’s clear that the reflections from the lights do not obey the assumed stereo geometry, as the reflection features do not shift between the left and right images. Therefore, it is not possible for algorithms that rely on pure feature matching to properly predict disparity under these conditions. A semantic understanding of the scene (knowledge that the bright pixels are reflections and not real objects) is needed to accurately predict the disparity in this region.
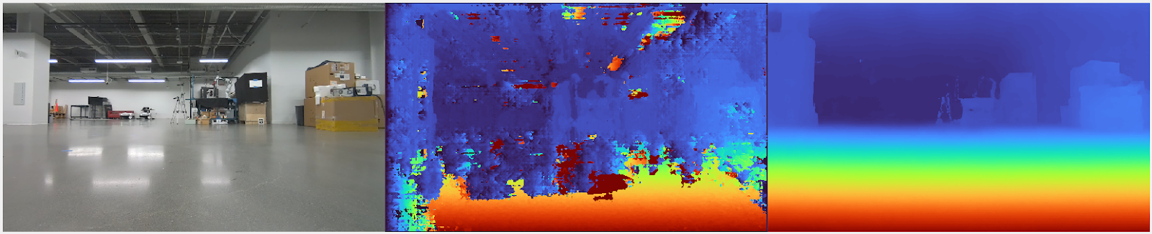
The following example shows a hallway containing flat and featureless surfaces, as well as bright specular reflections. The middle panel is a traditional stereo algorithm (SGM) with a noise filter applied, and the right panel is the output from a stereo DNN (ESS).

In many scenes that contain difficult or ill-posed regions, the best that a traditional stereo algorithm can do is filter out points. However, the use of filters carries an inherent trade-off between reducing noise and removing relevant information. Traditional image filtering can rarely be done in a context-dependent manner, and also adds additional latency and computation cost.
While the accuracy of AI-based stereo algorithms will suffer in difficult and ill-posed regions, and generally also need to be filtered, they offer the distinct ability to implicitly recognize these regions through training. In ESS, the model is trained to both predict the disparity as well as assess the predicted disparity accuracy using a “confidence” metric. This process allows the network to both use semantic understanding in the scene to better make disparity predictions, as well as estimate how good the prediction is. The result is a model output that allows for context dependent filtering based on scene understanding, leading to more dense and cleaner predictions.
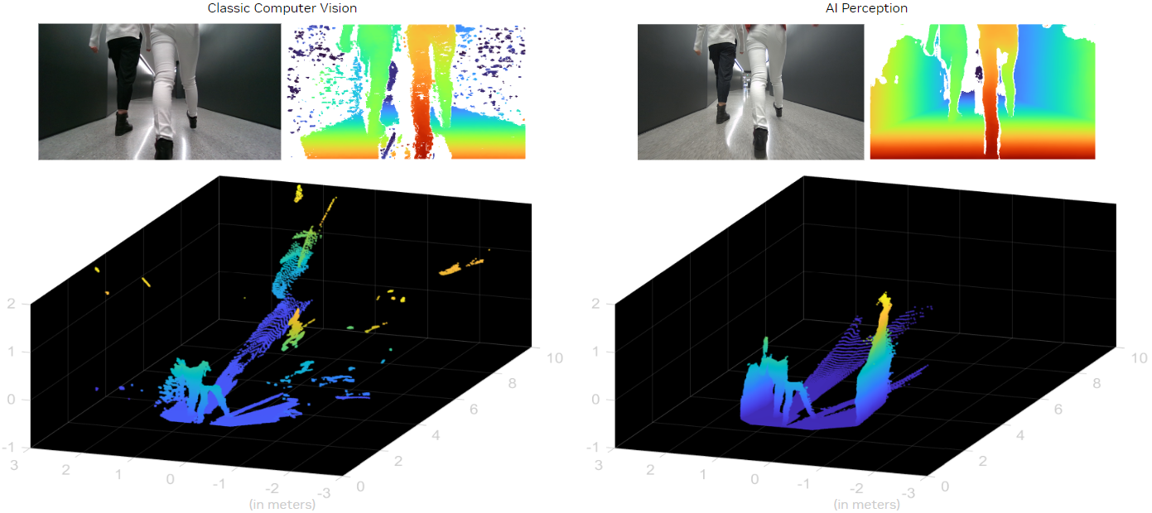
The following example compares a classic computer vision stereo algorithm (SGM) to a stereo DNN model (ESS). Both are filtered, and the resulting point cloud is displayed. The traditional stereo algorithm contains less 3D points, and those 3D points are noisier and less accurate. While more aggressive filtering can be applied, important points, such as the humans, will also inevitably get removed. The stereo DNN model, which outputs a context-aware confidence map, can preserve a lot more information about the scene while also removing inaccurate and noisy points.