Stereo Depth#
Much like human eyes, stereo vision works by measuring the displacement in pixels, or disparity, between two images of the same visually distinctive feature taken from two shifted imagers. With the measured disparity and the known length of the baseline (the distance between the two imagers), the distance to (or depth) of that visually distinct feature can be estimated.
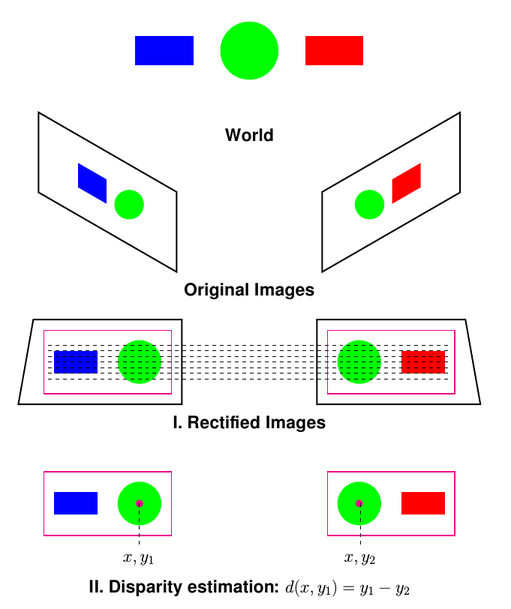
Stereo cameras have two monocular imagers rigidly attached to each other, facing in roughly the same direction. They are separated by some known baseline distance, typically on the scale of centimeters. The pair of images must be rectified by being projected onto the same epipolar plane using pre-calibrated stereo rectified parameters. The disparity in pixels between the same features in one image versus the other can be directly correlated to depth using the baseline and focal length of the imagers.
The disparity for each pixel cannot always be determined because it depends on the matching process. If the stereo camera is facing a featureless solid color wall, for example, there are no visually distinct features or corners (sharp variations in contrast) to match between images. To work around this issue, a few stereo cameras project a pattern of infrared light into the scene that both imagers can always see but that human eyes cannot.
By measuring the disparity for all pairs of matching features in a scene between two images, you can produce a disparity image where each pixel represents the disparity or a NaN when disparity can’t be calculated.
Using the baseline and focal length, this disparity image can then be used to produce a more familiar depth image where every pixel represents a depth in metric distances or a point cloud.
FoundationStereo is a pre-trained transformer-based foundation model that leverages large-scale training and depth-specific priors to achieve high-quality depth estimation across diverse environments.
Fast-FoundationStereo is a speed-optimized variant of FoundationStereo that achieves real-time zero-shot stereo matching through knowledge distillation, neural architecture search, and structured pruning. It uses the same Isaac ROS pipeline as FoundationStereo (
isaac_ros_foundationstereo) and serves as a drop-in replacement.ESS (efficient semi-supervised) is based on a deep-learned, pre-trained model available that can more intelligently handle smooth gradients and edges inferred from context.
SGM (semi-global matching) is a ubiquitous analytic algorithm for calculating stereo disparity. SGM has difficulty with smooth or regular surfaces and can suffer from excessive noise.