As of June 30, 2025, the Isaac ROS Buildfarm for Isaac ROS 2.1 on Ubuntu
20.04 Focal is no longer supported.
Due to an isolated infrastructure event, all ROS 2 Humble Debian packages
that were previously built for Ubuntu 20.04 are no longer available in the
Isaac Apt Repository. All artifacts for Isaac ROS 3.0 and later are built
and maintained with a more robust pipeline.
This quickstart demonstrates isaac_ros_triton in an image segmentation application.
Therefore, this demo features an encoder and decoder node to perform
pre-processing and post-processing respectively. In reality, the
raw inference result is simply a tensor.
To use the packages in other useful contexts, please refer
here.
Set up your development environment by following the instructions
here.
Clone isaac_ros_common, isaac_ros_image_segmentation, and this repository under ${ISAAC_ROS_WS}/src.
This result is not very useful friendly. It’s typically more desirable to see the network output after it’s decoded.
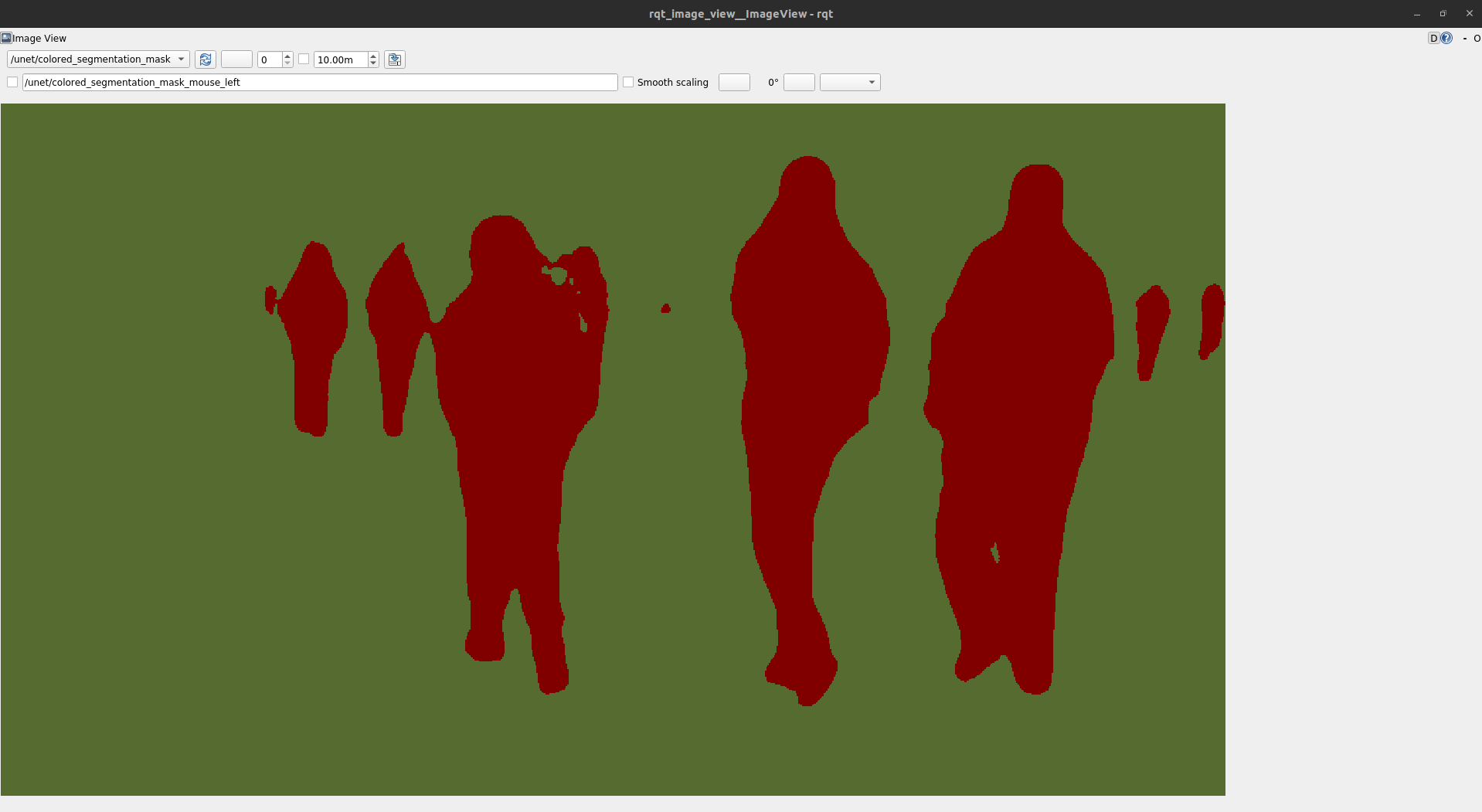
The result of the entire image segmentation pipeline can be visualized by launching rqt_image_view:
ros2runrqt_image_viewrqt_image_view
Then inside the rqt_image_view GUI, change the topic to /unet/colored_segmentation_mask to view a colorized segmentation mask.
Note
A launch file called isaac_ros_triton.launch.py is provided in this package to launch only Triton.
Warning
The Triton Inference node expects tensors as input and outputs tensors.
The node inference itself is generic; as long as the input data can be converted into a tensor, and
the model that is used is correctly trained on said input data.
For example, Triton can be used with models that are trained on images, audio and more, but
the necessary encoder and decoder node must be implemented.
This package contains a launch file that solely launches isaac_ros_triton.
Warning
For your specific application, these launch files may need to be modified. Please consult the available components to see
the configurable parameters.
Additionally, for most applications, an encoder node for pre-processing your data source and
decoder for post-processing the inference output is required.
The absolute paths to your model repositories in your local file system (the structure should follow Triton requirements) E.g. ['/tmp/models']
model_name
string
''
The name of your model. Under model_repository_paths, there should be a directory with this name, and it should align with the model name in the model configuration under this directory E.g. peoplesemsegnet_shuffleseg
max_batch_size
uint16_t
8
The maximum batch size allowed for the model. It should align with the model configuration
num_concurrent_requests
uint16_t
10
The number of requests the Triton server can take at a time. This should be set according to the tensor publisher frequency
input_tensor_names
stringlist
['input_tensor']
A list of tensor names to be bound to specified input bindings names. Bindings occur in sequential order, so the first name here will be mapped to the first name in input_binding_names
input_binding_names
stringlist
['']
A list of input tensor binding names specified by model E.g. ['input_2:0']
input_tensor_formats
stringlist
['']
A list of input tensor NITROS formats. This should be given in sequential order E.g. ['nitros_tensor_list_nchw_rgb_f32']
output_tensor_names
stringlist
['output_tensor']
A list of tensor names to be bound to specified output binding names
output_binding_names
stringlist
['']
A list of tensor names to be bound to specified output binding names E.g. ['argmax_1']
output_tensor_formats
stringlist
['']
A list of input tensor NITROS formats. This should be given in sequential order E.g. [nitros_tensor_list_nchw_rgb_f32]