Attention
As of June 30, 2025, the Isaac ROS Buildfarm for Isaac ROS 2.1 on Ubuntu 20.04 Focal is no longer supported.
Due to an isolated infrastructure event, all ROS 2 Humble Debian packages that were previously built for Ubuntu 20.04 are no longer available in the Isaac Apt Repository. All artifacts for Isaac ROS 3.0 and later are built and maintained with a more robust pipeline.
Users are encouraged to migrate to the latest version of Isaac ROS. The source code for Isaac ROS 2.1
continues to be available on the release-2.1 branches of the Isaac ROS
GitHub repositories.
The original documentation for Isaac ROS 2.1 is preserved below.
DNN Inference
Overview
DNN (deep neural network) inference is the computational process involved with feeding input through a pretrained neural network model to infer or predict an output. The input, such as images, text, or audio, must first be encoded or pre-processed into a set of tensors (collection of numbers). Similarly, the output is a set of tensors that must be decoded or post-processed into a semantically meaningful output (e.g., text, image, image masks, poses, pixel coordinates, etc.).
In robotics, DNN inference is often used to wire streams of sensor data through an encoder which feeds into a DNN inference package that has been loaded with a model capable of predicting useful outputs that lead to intelligent behaviors. For example, monocular camera images can be fed to a DNN inference framework such as TensorRT configured with a YOLOv8 model pre-trained for detecting cats. Streams of images are encoded as tensors and fed into TensorRT to run inference over the model to predict tensors that are interpreted by a YOLOv8 decoder as a set of bounding boxes in pixel coordinates. This information can now be used could be used in a variety of intelligent behaviors such as stopping the robot until said cat has lost interest in your roaming robot.
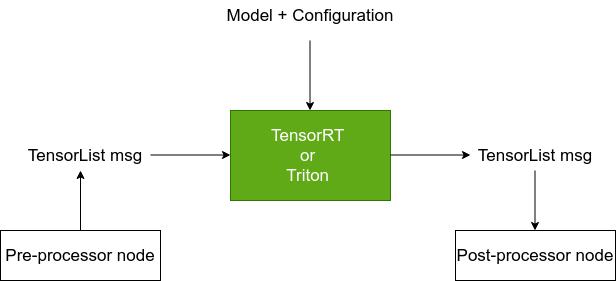
Resources
For more information on deep learning, see NVIDIA Developer for Deep Learning.
For more information on Triton and TensorRT, click here.
For more models to use in your robotics application, click here.
Repositories and Packages
We provide decoders for a variety of model architectures for various tasks:
Package Name |
Use Case |
|---|---|
Deep learned stereo disparity estimation |
|
Hardware-accelerated, deep learned semantic image segmentation |
|
Deep learning model support for object detection including DetectNet |
|
Deep learned, hardware-accelerated 3D object pose estimation |
|
DNN-based depth segmentation and obstacle field ranging using Bi3D |