Attention
As of June 30, 2025, the Isaac ROS Buildfarm for Isaac ROS 2.1 on Ubuntu 20.04 Focal is no longer supported.
Due to an isolated infrastructure event, all ROS 2 Humble Debian packages that were previously built for Ubuntu 20.04 are no longer available in the Isaac Apt Repository. All artifacts for Isaac ROS 3.0 and later are built and maintained with a more robust pipeline.
Users are encouraged to migrate to the latest version of Isaac ROS. The source code for Isaac ROS 2.1
continues to be available on the release-2.1 branches of the Isaac ROS
GitHub repositories.
The original documentation for Isaac ROS 2.1 is preserved below.
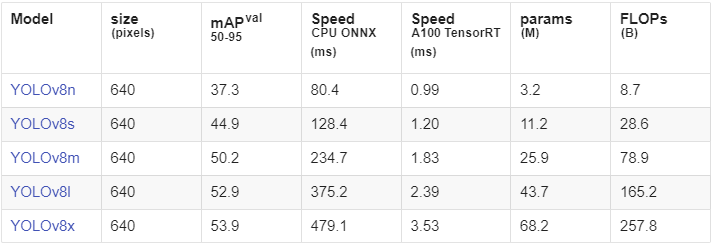
YOLOv8
YOLOv8 is a state-of-the-art, real-time model for perception tasks including object detection, tracking, segmentation, classification, and pose estimation.
YOLOv8 is pre-trained on the COCO dataset to perform object detection out of the box for 80 object classes. It offers various size options (nano/small/medium/large/extra-large) to apply to different use cases. Model size is proportional to accuracy and inversely proportional to inference time. Smaller models are appropriate for resource-constrained devices used in edge scenarios while larger models are useful where there’s less data.
Advantages of YOLOv8:
High speed and accuracy
Adaptable to different hardware platforms, from CPUs to GPUs and cloud
Offers developer-friendly features including easy CLI and Python packages
How YOLOv8 Works
A neural network uses multiple detection heads to resolve objects of different scales in an image. YOLOv8 has 3 detection heads that each look at the input image with a different stride. It outputs three feature maps at different scales - 80x80, 40x40 and 20x20.
YOLOv8 outputs a tensor of size (1, 8400, 84) for an input image. Here, 1 represents the batch size and 8400 represents output from the three feature maps - (80x80 + 40x40 + 20x20). 84 represents the bounding box and class probability information (bounding box ‘x’ coordinate, ‘y’ coordinate, height and width + 80 class probabilities). You can filter candidate detections based on the detection score during post processing.
YOLOv8 performs anchor-free detection, which means it predicts an object’s center directly instead of predicting the offset from an anchor box (visualization below). This speeds up the post processing step of Non-Maximum Suppression (NMS) by reducing the number of candidate predictions.
Repositories and Packages
The Isaac ROS implementations of this technology are available here: