Attention
As of June 30, 2025, the Isaac ROS Buildfarm for Isaac ROS 2.1 on Ubuntu 20.04 Focal is no longer supported.
Due to an isolated infrastructure event, all ROS 2 Humble Debian packages that were previously built for Ubuntu 20.04 are no longer available in the Isaac Apt Repository. All artifacts for Isaac ROS 3.0 and later are built and maintained with a more robust pipeline.
Users are encouraged to migrate to the latest version of Isaac ROS. The source code for Isaac ROS 2.1
continues to be available on the release-2.1 branches of the Isaac ROS
GitHub repositories.
The original documentation for Isaac ROS 2.1 is preserved below.
Isaac ROS Triton and TensorRT Nodes for DNN Inference
NVIDIA Isaac ROS provides two separate packages for performing DNN inference: Triton and TensorRT.
Our benchmarks show comparable performance and inference speed with both nodes, so a decision should be based on other characteristics of the overall model being deployed.
NVIDIA Triton
The NVIDIA Triton Inference Server is an open-source inference serving software that provides a uniform interface for deploying AI models. Crucially, Triton supports a wide array of compute devices like NVIDIA GPUs and both x86 and ARM CPUs, and also operates with all major frameworks such as TensorFlow, TensorRT, and PyTorch.
Because Triton can take advantage of additional compute devices beyond just the GPU, Triton can be a better choice in situations where there is GPU resource contention from other model inference or processing tasks. However, in order to provide for this flexibility, Triton requires the creation of a model repository and additional configuration files before deployment.
NVIDIA TensorRT
NVIDIA TensorRT is a specific CUDA-based, on-GPU inference framework that performs a number of optimizations to deliver extremely performant model execution. TensorRT only supports ONNX and TensorRT Engine Plans, providing less flexibility than Triton but also requiring less initial configuration.
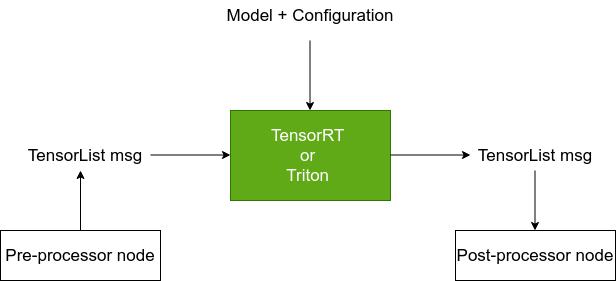
Using either Triton or TensorRT Nodes
Both nodes use the Isaac ROS Tensor List message for input data and output inference result.
Users can either prepare a custom model or download pre-trained models
from NGC as described here.
Models should be converted to the TensorRT Engine File format using the
tao-converter tool as described
here.
Note: While the TensorRT node can automatically convert ONNX plans to the TensorRT Engine Plan format if configured to use a
.onnxfile, this conversion step will considerably extend the node’s per-launch initial setup time.As a result, we recommend converting any ONNX models to TensorRT Engine Plans first, and configuring the TensorRT node to use the Engine Plan instead.
Pre- and Post-Processing Nodes
In order to be a useful component of a ROS graph, both Isaac ROS Triton
and TensorRT inference nodes will require application-specific
pre-processor (encoder) and post-processor (decoder)
nodes to handle type conversion and other necessary steps.
A pre-processor node should take in a ROS 2 message, perform the
pre-processing steps dictated by the model, and then convert the data
into an Isaac ROS Tensor List message. For example, a pre-processor
node could resize an image, normalize it, and then convert it into a
Tensor List.
A post-processor node should be used to convert the Isaac ROS Tensor
List output of the model inference into a useful ROS 2 message. For
example, a post-processor node may perform argmax to identify the
class label from a classification problem.
Further Reading
For more documentation on Triton, see here.
For more documentation on TensorRT, see here.