Isaac ROS DNN Stereo Depth#

Overview#
Deep Neural Network (DNN)–based stereo models have become essential for depth estimation because they overcome many of the fundamental limitations of classical and geometry-based stereo algorithms.
Traditional stereo matching relies on explicitly finding pixel correspondences between left and right images using handcrafted features. While effective in well-textured, ideal conditions, these approaches often fail in “ill-posed” regions such as areas with reflections, specular highlights, texture-less surfaces, repetitive patterns, occlusions, or even minor camera calibration errors. In such cases, classical algorithms may produce incomplete or inaccurate depth maps, or be forced to discard information entirely, especially when context-dependent filtering is not possible.
DNN-based stereo methods learn rich, hierarchical feature representations and context-aware matching costs directly from data. These models leverage semantic understanding and global scene context to infer depth, even in challenging environments where traditional correspondence measures break down. Through training, DNNs can implicitly account for real-world imperfections such as:
calibration errors
exposure differences
hardware noise
Training increases DNN’s ability to recognize and handle difficult regions like reflections or transparent surfaces. This results in more robust, accurate, and dense depth predictions.
These advances are critical for robotics and autonomous systems, enabling applications where both speed and accuracy of depth perception are essential, such as:
precise robotic arm manipulation
reliable obstacle avoidance and navigation
robust target tracking in dynamic or cluttered environments
DNN-based stereo methods consistently outperform classical techniques, making them the preferred choice for modern depth perception tasks.
The superiority of DNN-based stereo methods is clearly demonstrated in the figure above where we compare the output from a classical stereo algorithm, SGM, with DNN-based methods, ESS, and FoundationStereo.
SGM produces a very noisy and error-prone disparity map, while ESS and FoundationStereo produce much smoother and more accurate disparity maps. A closer look reveals that FoundationStereo produces the most accurate map because it is better at handling the plant in the distance and the railings on the left with smoother estimates. Overall, you can see that FoundationStereo is better than ESS, and better than SGM, in terms of accuracy and quality.
DNN‐based stereo systems begin by passing the left and right images through shared Convolutional backbones to extract multi‐scale feature maps that encode both texture and semantic information. These feature maps are then compared across potential disparities by constructing a learnable cost volume, which effectively represents the matching likelihood of each pixel at different disparities. Successive 3D Convolutional (or 2D convolution + aggregation) stages then regularize and refine this cost volume, integrating strong local cues—like edges and textures—and global scene context—such as object shapes and layout priors—to resolve ambiguities. Finally, a soft‐argmax or classification layer converts the refined cost volume into a dense disparity map, often followed by lightweight refinement modules that enforce sub-pixel accuracy and respect learned priors (for example, smoothness within objects, sharp transitions at boundaries), yielding a coherent estimate that gracefully handles challenging scenarios where classical algorithms falter.
Applications#
The vision depth perception problem is generally useful in many fields of robotics such as estimating the pose of a robotic arm in an object manipulation task, estimating distance of static or moving targets in autonomous robot navigation, tracking targets in delivery robots and so on. Isaac ROS DNN Stereo Depth is targeted at various applications including manipulation where ESS is deployed with Isaac ROS cuMotion package as a plug-in node to provide depth perception maps for robot arm motion planning and control. Besides these, the DNN-based stereo models, ESS and FoundationStereo, can be used in other applications supported by Isaac ROS to infer depth from stereo images obtained from a variety of sources such as Isaac Sim, RealSense camera, and ZED camera.
Quickstarts#
Isaac ROS NITROS Acceleration#
This package is powered by NVIDIA Isaac Transport for ROS (NITROS), which leverages type adaptation and negotiation to optimize message formats and dramatically accelerate communication between participating nodes.
ESS DNN#
ESS stands for Efficient Semi-Supervised stereo disparity, developed by NVIDIA. The ESS DNN is used to predict the disparity for each pixel from stereo camera image pairs.
This network has improvements over classic CV approaches that use epipolar geometry to compute disparity, because the DNN can learn to predict disparity in cases where epipolar geometry feature matching fails. The semi-supervised learning and stereo disparity matching makes the ESS DNN robust in environments unseen in the training datasets and with occluded objects. This DNN is optimized for and evaluated with color (RGB) global shutter stereo camera images. Accuracy may vary with monochrome stereo images used in analytic computer vision approaches to stereo disparity.
It is a relatively light model that runs at near real-time speeds.

As seen in the figure, the ESS node is used in a graph of nodes to provide a disparity prediction from an input left and right stereo image pair.
The rectify and resize nodes pre-process the left and right frames to the appropriate resolution. Maintain the aspect ratio of the image to avoid degrading the depth output quality. The graph for DNN encode, DNN inference, and DNN decode is included in the ESS node. Inference is performed using TensorRT, because the ESS DNN model is designed with optimizations supported by TensorRT.
FoundationStereo DNN#
FoundationStereo is a foundation model for stereo depth estimation developed by NVIDIA. It is designed to predict the disparity for each pixel from stereo camera image pairs.
FoundationStereo advances beyond traditional computer vision and earlier deep learning approaches by leveraging a transformer-based architecture and large-scale training on diverse datasets. Notably, its feature extractor incorporates depth-specific priors through the use of the Depth Anything V2 model, further enhancing its ability to generalize across scenes.
This enables the model to generalize robustly to new environments, camera types, and challenging scenarios such as varying lighting, occlusions, and non-standard camera parameters, where classic epipolar geometry or feature matching may fail.
The model is optimized for accurate and reliable disparity estimation across a wide range of domains, outperforming previous methods in both benchmark performance and zero-shot transfer to unseen datasets. The model works best with color (RGB) stereo images and accuracy may vary with monochrome stereo images.
It is a heavy model that is best-suited for applications that do not require real-time performance.
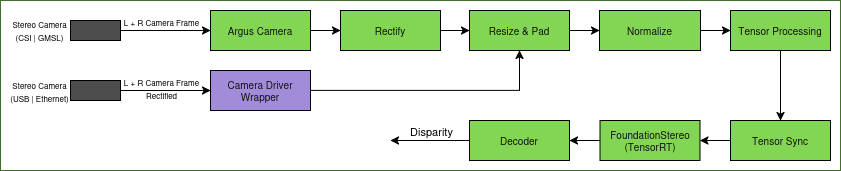
As seen in the figure, FoundationStereo is used in a graph of nodes to provide a disparity prediction from an input left and right stereo image pair. The input images may need to be rectified to handle distortions. They may also need to be resized and padded to match the input resolution of the model. The aspect ratio of the image is recommended to be maintained to avoid degrading the depth output quality.
isaac_ros_tensor_proc provides DNN encoder nodes to process the input images into
Tensors for the model. Inference is performed using TensorRT, as the model is designed with optimizations supported by
TensorRT.
The decoder node takes the model output and converts it into a disparity map with some post-processing.
DNN Output#
The predicted disparity values represent the distance a point moves from one image to the other in a stereo image pair (the binocular image pair). The disparity is inversely proportional to the depth:
Given the focal
length and
baseline of the camera
that generates a stereo image pair, the predicted disparity map from the isaac_ros_ess
and the isaac_ros_foundationstereo packages can be used to compute depth and generate a
point cloud.
Comparing DNNs#
Attribute |
ESS |
FoundationStereo |
|---|---|---|
Outputs |
Disparity map + confidence map (used for filtering disparity) |
Disparity map only |
Resolution |
576 x 960 + 288 x 480 (Light ESS) |
576 x 960 + 320 x 736 |
Parameter Count |
17 million |
60.6 million |
BP2 (Middlebury 576x960) |
8.27 |
5.306 |
MAE (Middlebury 576x960) |
1.06 |
0.775 |
Model Throughput (AGX Orin) |
108.86 FPS |
1.77 FPS |
Applications |
Use-cases where real-time depth estimates are required. |
Use-cases where quality of predictions is more crucial than speed and some latency is acceptable. |
In the above table, BP2 measures the percentage of bad pixels which deviate more than the threshold value of 2 pixels from the ground truth. MAE measures the mean absolute error. Lower BP2 and MAE values indicate better performance.
DNN Models#
ESS#
An ESS model is required to run isaac_ros_ess.
NGC provides pre-trained models for use in your robotics application.
ESS models are available on NGC, providing robust
depth estimation.
Click here for more information on how to use NGC models.
Confidence and Density#
ESS DNN provides two outputs: disparity estimation and confidence estimation.
The disparity output can be filtered, by thresholding the confidence output,
to trade-off between confidence and density.
isaac_ros_ess filters out pixels with low confidence by setting:
disparity[confidence < threshold] = -1 # -1 means invalid
The choice of threshold value is dependent on use case.

Resolution and Performance#
NGC provides ESS and Light ESS models for trade-off between resolution and performance. A detailed comparison of the two models can be found here.
Model Name |
Disparity Resolution |
|---|---|
ESS |
Estimate disparity at 1/4 HD resolution |
Light ESS |
Estimate disparity at 1/16 HD resolution |
DNN Plugins#
ESS TensorRT custom plugins are used to optimize the ESS DNN for inference on NVIDIA GPUs. The plugins work with custom layers added in ESS model and they are not natively supported by TensorRT. ESS prebuilt plugins are available for Jetson Thor and x86_64 platforms. The plugins are used during the conversion of the ESS model to TensorRT engine plan, as well as during TensorRT inference. ESS TensorRT custom plugins are available for download from NGC together with ESS models.
FoundationStereo#
A FoundationStereo model can be used to run isaac_ros_foundationstereo. Pre-trained FoundationStereo models are available on NVIDIA NGC for robust depth estimation in robotics applications.
Disparity Output#
FoundationStereo provides a single output:
disparity estimation
Unlike ESS models, FoundationStereo does not output a confidence map. As a result, there is no confidence-based filtering of the disparity output. All estimated disparity values are provided directly by the model.
Resolution and Performance#
FoundationStereo models are designed for high-quality disparity estimation. NGC provides models at two different resolutions: 576x960 and 320x736. For details on available models and their performance characteristics, refer to the NGC FoundationStereo page.
Packages#
Supported Platforms#
This package is designed and tested to be compatible with ROS 2 Jazzy running on Jetson or an x86_64 system with an NVIDIA GPU.
Platform |
Hardware |
Software |
Storage |
Notes |
|---|---|---|---|---|
Jetson |
128+ GB NVMe SSD |
For best performance, ensure that power settings are configured appropriately. |
||
x86_64 |
|
32+ GB disk space available |
Isaac ROS Environment#
To simplify development, we strongly recommend leveraging the Isaac ROS CLI by following these steps. This streamlines your development environment setup with the correct versions of dependencies on both Jetson and x86_64 platforms.
Note
All Isaac ROS Quickstarts, tutorials, and examples have been designed with the Isaac ROS CLI-managed environment as a prerequisite.
Customize your Dev Environment#
To customize your development environment, refer to this guide.
Updates#
Date |
Changes |
|---|---|
2025-10-24 |
Added FoundationStereo package |
2024-09-26 |
Updated for ESS 4.1 trained on additional samples |
2024-05-30 |
Updated for ESS 4.0 with fused kernel plugins |
2023-10-18 |
Updated for ESS 3.0 with confidence thresholding in multiple resolutions |
2023-05-25 |
Upgraded model (1.1.0) |
2023-04-05 |
Source available GXF extensions |
2022-10-19 |
Updated OSS licensing |
2022-08-31 |
Update to be compatible with JetPack 5.0.2 |
2022-06-30 |
Initial release |